Designing a Robust Web Crawler - From Requirements to Implementation
Designing a Robust Web Crawler - From Requirements to Implementation
What is a web crawler?
A web crawler is a bot that downloads and indexes contents from all over the internet. The goal of such bot is to learn what every page on the web is about, so the information can be retrieved when needed. - Cloudflare
We need to overcome a few obstacles while designing our web crawler
There are billions of web pages so are system should be** efficient in terms of memory and CPU usage**
It should be scalable (Especially horizontally scalable). Because as the web grows we can add more machines to compensate for that.
It should be fast. Our system should be able to process hundreds (or even thousands) of web pages in one second.
Web servers have implicit and explicit policies regulating the rate at which a crawler can visit them. These politeness policies must be respected.
It should crawl high-quality web pages frequently. The priority of a page should be a function of both its change rate and its quality
Let’s list down the steps required while crawling websites and build components for each step
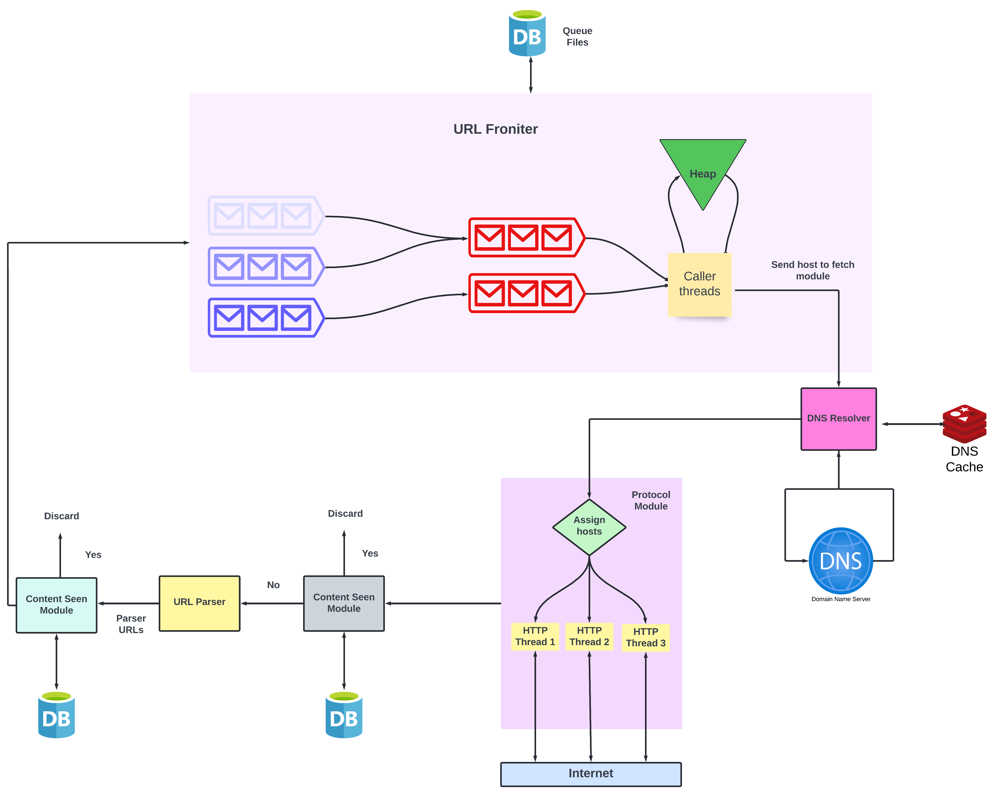
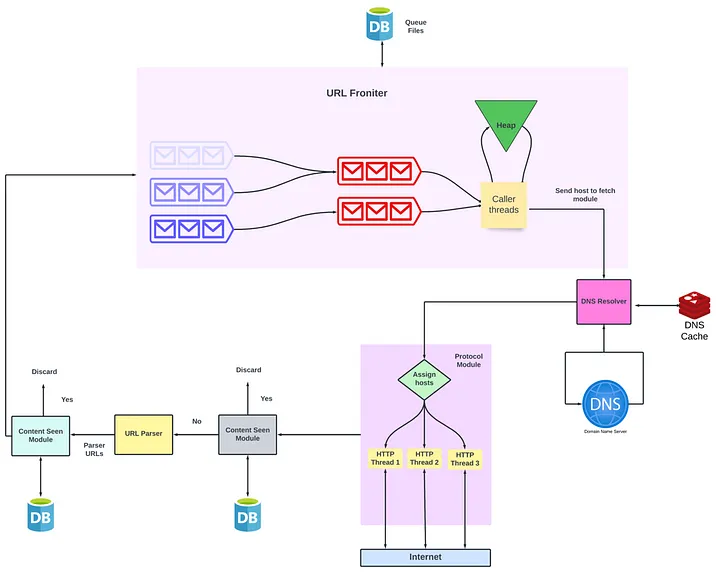
Get the URL to be crawled from the queue (It’s called an URL frontier but we will get to that later)
Use DNS resolution to find the IP Address of the web page
Fetch the HTML content from the web page
If the content is already seen then discard the page
Parse the content and get all the anchor tags on the page. These anchor tags contain the next set of URLs. If the URLs are not seen then these URLs are added to the URL frontier.
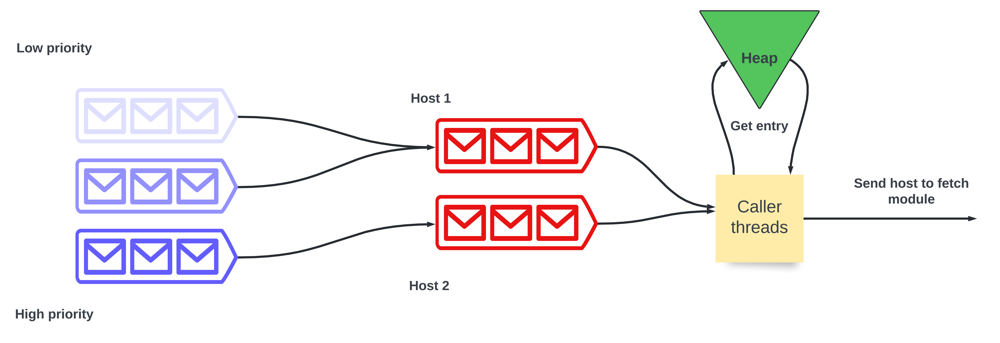
Designing the URL Frontier
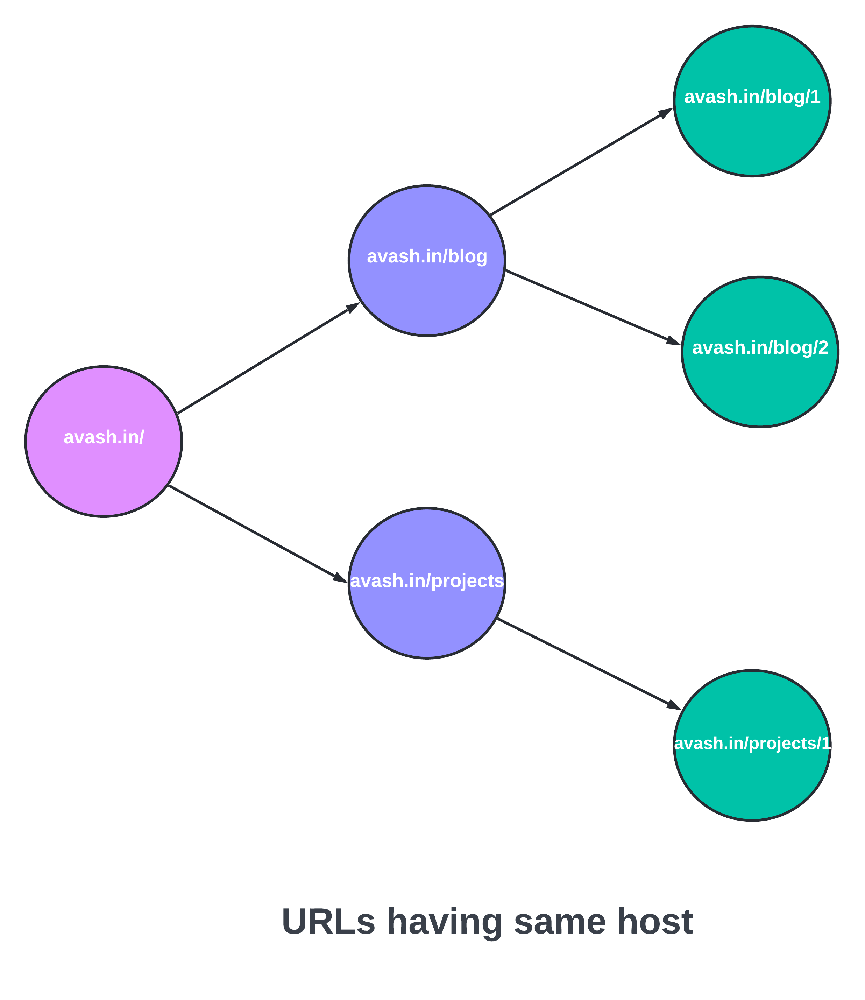
Before discussing the design of URL frontier, let’s discuss why don’t we use a standard queue. Well, a standard queue is FIFO. In the case of crawling, it is unacceptable because the in a page most URLs point to other pages hosted on the same server.
This can cause two types of problems
If we send the requests serially, We will be sending a burst of requests to the same server i.e., we will be spamming the server
If we send requests in parallel, the head of the queue would return an URL whose server has no outstanding requests.
Note: This implementation of URL frontier is based on the implementation in the Mercator web crawler
Components of URL frontiers are :
Front queues - This set of queues implement prioritization. Each queue has a priority label. The higher the priority, the sooner the URL popped from the queue.
Back queues - This set of queues implement politeness. Each queue contains URLs from only one host.
Min - Heap - There is one entry for each back queue. Each entry contains the server/host address and the earliest time when the request can be made (let’s say t).
Caller threads - When we extract an URL from the back queue this thread group fetches the URLs and assigns URLs to the back queues.
How URL Frontier works:
The caller thread pops the top of the heap and waits for t seconds.
It gets the URL from the back queue and makes a fetch request.
If the back queue is not empty, it repeats the process.
If the back queue is empty (let’s call this queue x), it picks one of the front queues (usually biased towards higher priority queues) and picks a URL from there.
Keep in mind, each back queue holds URLs belonging to the same host. So it checks if the URL’s host is there in any back queue then the URL is pushed to that back queue.
If no queue is found it is pushed into back queue x and a new entry is added to the heap.
Well, if this feels overwhelming, don’t worry. Here’s the flow chart that summarizes all of it properly.
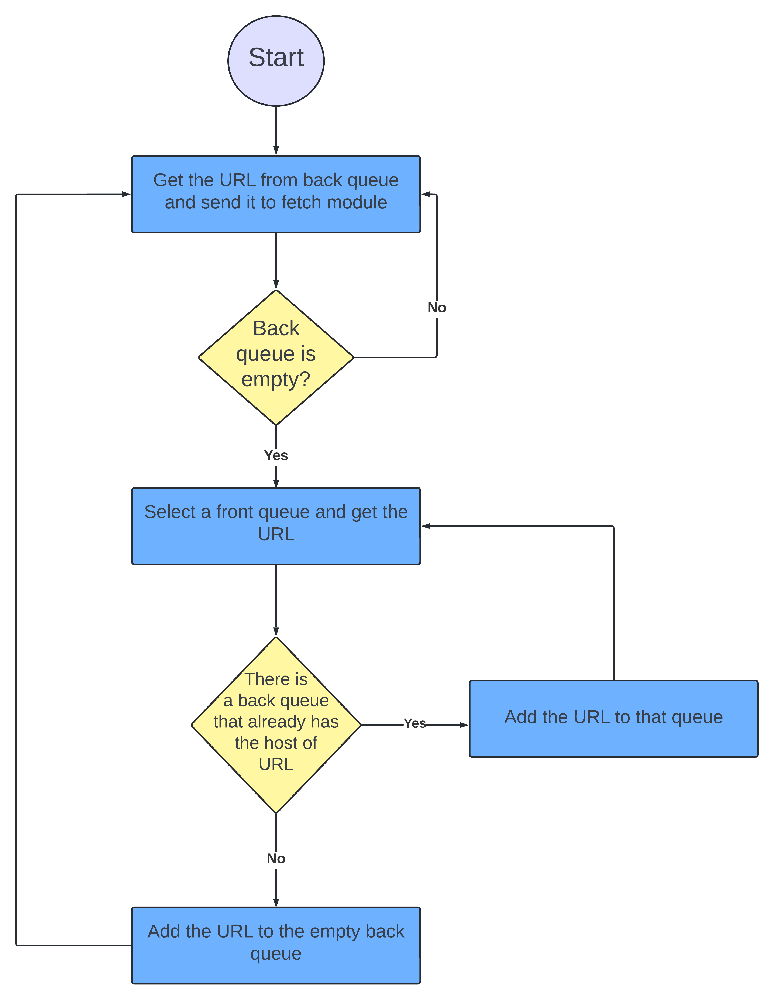
Diagram of URL Frontier
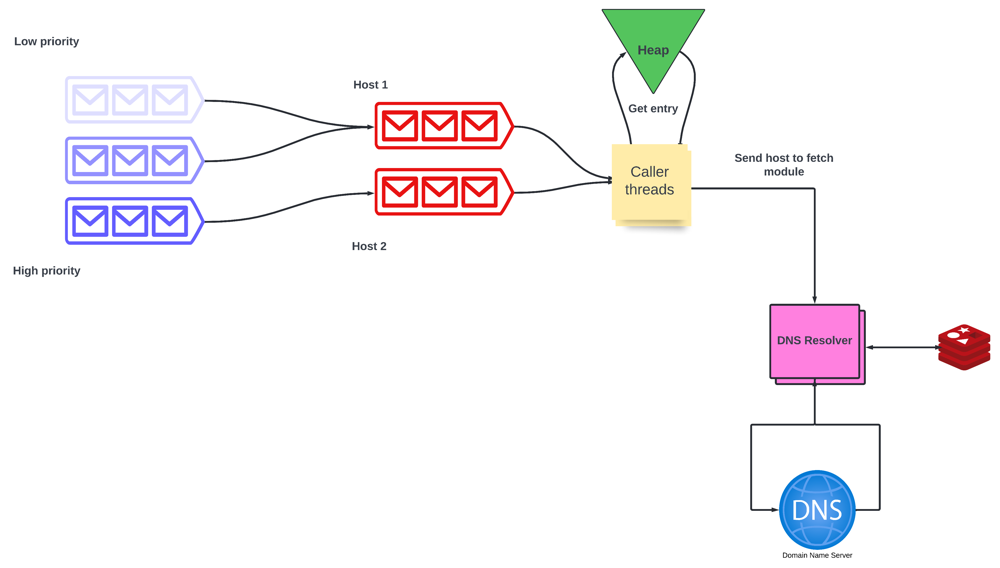
Overcoming the bottleneck of DNS Resolution
DNS Resolution is the process of finding the IP Address of a web page from its URL. In this process, we make requests to Domain Name Service and get the IP Address in response. We won’t go into the details of how DNS resolution works but it can take multiple requests before we get the IP Address, so it can take a few seconds per request. This is unacceptable since we need to index hundreds of pages per second.
We can solve this bottleneck by
Caching the IP Addresses - We can use cache to store the key-value pair of hostname and IP address.
Fetching the IP Addresses asynchronously - When we are performing synchronous lookups the crawler thread is blocked until we get the IP Address, to prevent this we can use multi-threading for performing DNS lookups in parallel.
- We have separate worker threads that send requests to the DNS servers. Then it sleeps for a specified amount of time and only wakes up when the time quantum expires or another thread wakes it up
- Another single separate thread is listening to the standard DNS port. Upon receiving the response send it to the appropriate thread (one of the worker threads).
- If the thread does not receive the IP Address in a specified amount of time it makes a retry. There is a limit to the number of requests. If the lookup fails and the maximum number of retries is reached then it is aborted.
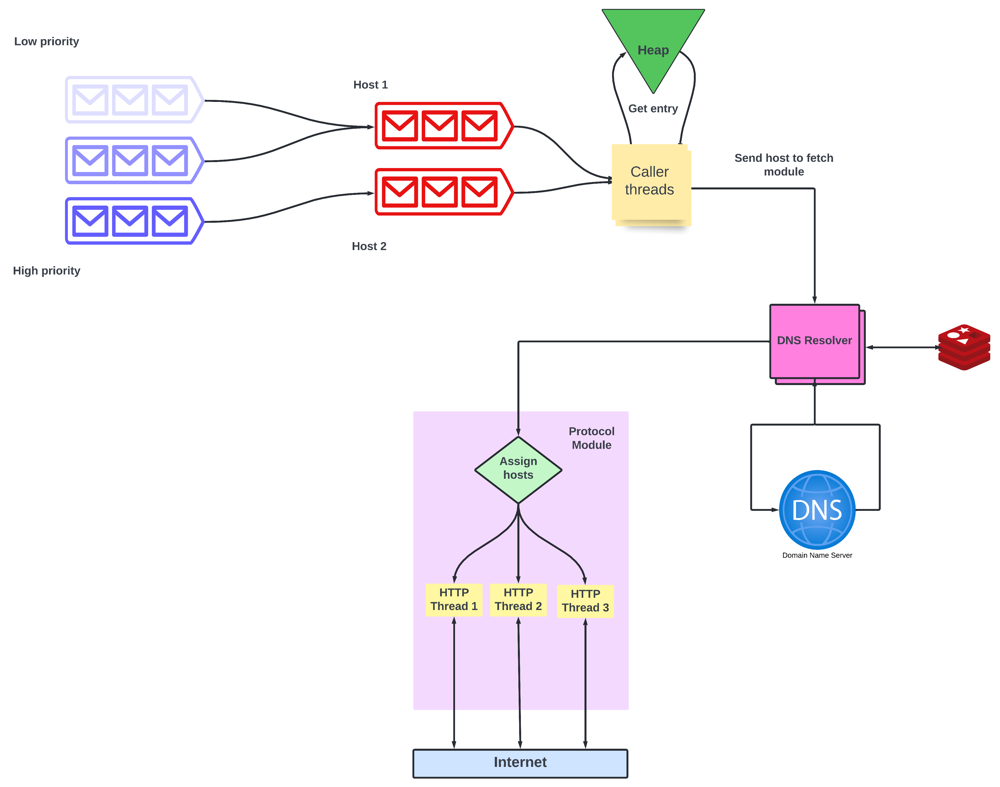
Fetching content from the web page
We will be fetching the webpage corresponding to a given URL using the appropriate network protocol. There can be multiple protocols like HTTP, FTP, etc.
Each fetch module will have multiple worker threads to make sure that there is no blocking.
To prevent the crawler from sending bursts of requests to the same host, we assign each host to one particular thread. We can achieve this by hashing the hostname and then assigning it to the thread.
- For example, if there are threads from 0 to N, then we can use the hash function h(host_name)%N. The result is the thread number.
Also, we must specify the maximum number of retries while fetching the content. If the number of tries exceeds it we will abort the process.
Designing the ‘Content Seen’ Module
If we use the naive approach, we store the entire content of a web page (either in cache or in secondary memory), and then whenever we get a new web page we compare it with the previous one.
This approach is simple, but it consumes a lot of time and memory. So, we won’t be using this.
Instead, we use a structure called the document fingerprint set that stores a 64-bit checksum of the contents of each web page. Fingerprints offer provably strong probabilistic guarantees that two different strings will not have the same fingerprint.
It also consumes less memory and time.
The implementation of content seen module in Mercator uses Broder’s implementation of Rabin’s fingerprinting algorithm.
Like all other modules, we will have multiple worker threads to process web pages in parallel.
Designing the ‘URL Seen’ Test
This one seems really similar to the ‘content seen’ test. We can calculate the fingerprint for each URL and compare it with the rest.
While this approach works, it is far more efficient to hash the URL and store it for comparison. But there can be false positives if we just use the hash function so we use a data structure called Bloom Filters.
We won’t go into much detail about the working of bloom filters, but here’s a short explanation
It uses a large bit vector (only contains 0s and 1s). An element is added to the set by computing n hash functions of the element and setting the corresponding bits. An element is deemed to be in the set if the bits at all n of the element’s hash locations are set.
By using a bloom filter
- We make sure that a fixed amount of memory is used.
- There are no false negatives and the probability of false positives is very less.
If the URL is not seen we add it to the URL Frontier and repeat the process.
Now that we are done, let’s look at how our final architecture of web crawler looks